
First we guess it. Then we compute the consequences of the guess to see what would be implied if this law that we guessed is right. Then we compare the result of the computation to nature, with experiment or experience, compare it directly with observation, to see if it works. If it disagrees with experiment it is wrong.
In that simple statement lies the most powerful tool we humans have ever used. It is fool-proof and self-correcting. The scientific method indeed is used for all manner of things not least of which IT monitoring, at least thats how we perceive things at Spearhead.
Applying the scientific method directly to IT monitoring is difficult for many reasons but the process we propose follows a scientific method which will help you reduce the signal to noise ratio. That process is as follows:
Monitor everything (even if you do not think it matters you want all observable metrics)
Fine tune your monitoring (what are important metrics, what are the thresholds, should we alert on the first or nth occurance, etc.)
Automate (self-repairing systems are nice)
If you imagine the above in a loop you will have a continously improving system. The automation part is optional although if your systems can repair themselves that is, we believe, a very good thing. The key to the above process is that it is not a “one fell swoop” type of solution. It is an incremental, step by step process whereby in each step you get better visibilty, more stability and less noise from the system (much in the the same way that scientists use the scientifc method to find out the nature of reality). It is important to note that on your first try you may not get the deisred results (i.e. false alarms or some other desired state) but you will be with each progression one step closer to your desired results. It is also important to note that you will not reach perfection.
Some things will fall through the cracks for varying reasons, what this process does is provide you with a proven method to delivering your desired results. So lets get down to business. The first step is to monitor everything. When I say everything I literally mean _everything_ . The reason for this is that we cannot know where exactly our systems break so it is useful to monitor _everything_ as in time we will learn these patterns and be better prepared to handle them. Within Checkmk this is quite easy as the agent auto-discovers everything and nicely lets you select what and how to monitor during a Service discovery.
Here is an example of the Service discovery screen where you can select what to monitor and later we will drill down to define _how_ to monitor that specific service.
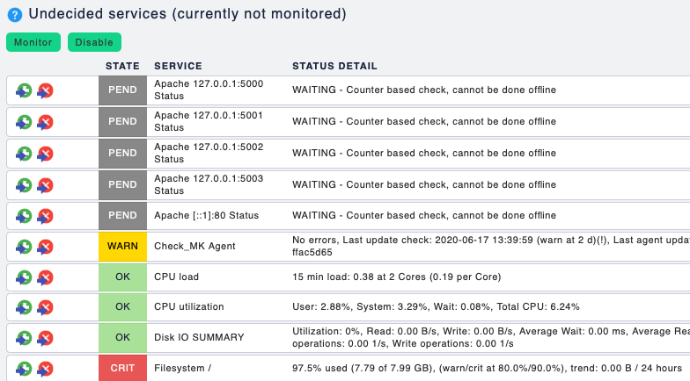
Now that we are monitoring things make sure you or a small team of people involved in the rollout of this service can receive notifications. For every notiffication you will have to do some work to identify the nature and get a _feel_ for the system to understand where and how things break or at the very least to understand why Checkmk considers them as such and triggers alerts/notifications. I find that asking questions such as the following help categorise this service:
further update thresholds
enable predictive monitoring
use notification delays
change check attempts/retries.
The above are a way to work around the problem specifically when it is recurring sporadically. Once your inbox is sane you can go ahead and configure your notification rules (contact groups and other settings) to deliver emails to your colleagues as well. Just remember, this is one iteration and systems are generally not static, things change or evolve. You will have to revisit your configuration and update accordingly when things no longer match your desired state. There is also a simple thing I notice at many customer sites that are dealing with a high signal to noise ratio and that is, sending notification for things nobody cares about and during a timeperiod that is not of importance. If there is no one to look at the notification and there is no impact of the sytesm being down, you should most likely should consider handling it during some other time period.

Not too complex right? It is a simple, iterative process by which you can bring insight and visibility into IT montioring process without loosing your mind weaving through endless monitoring alerts. If your would like more information please visit https://spearhead.systems/full-stack-obervability and make sure you sign-up for a live demo to get more details.